
- Part 1: Development in PI Design (IR)
- Part 2: Development in Conversion Agent Studio
- Part 3: Deploying Conversion Agent Project
- Part 4: Development in PI Configuration (ID)
- Part 5: Test the Scenario
Development in Conversion Agent Studio
Open the CA Studio and create a new Project with type parser as shown
Select Project type as Parser
Enter name of the Project
Enter name of the Parser
Enter name of the Parser Script
Select the Schema
Select the PDF file
Select PDF option
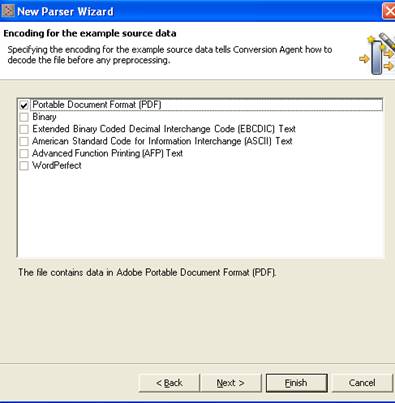
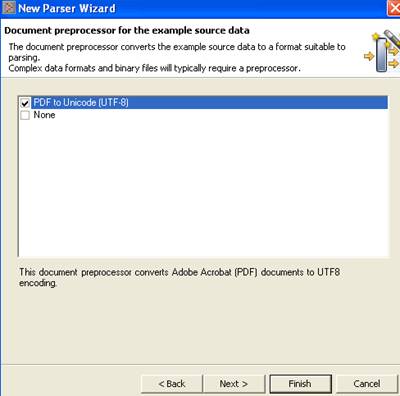
Select PDF to Unicode (UTF-8)
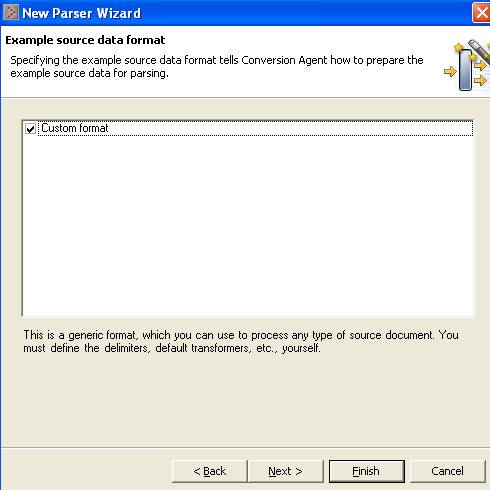
Select Custom Format
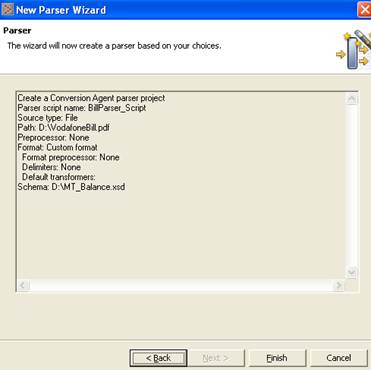
Say finish.
Open the Project node in Conversion Agent Explorer and double click on BillParser_Script.tgp file and start development as shown below:
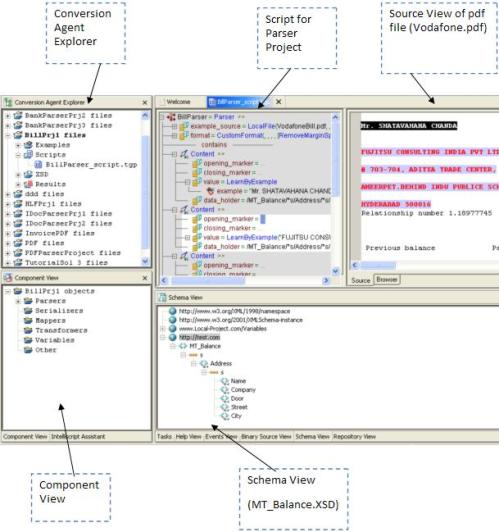
Now go through the Method-1 and Method-2, and select either of the methods, but Method-2 is always suggestible.
Method-1: Select the text and Drag directly to element in Schema
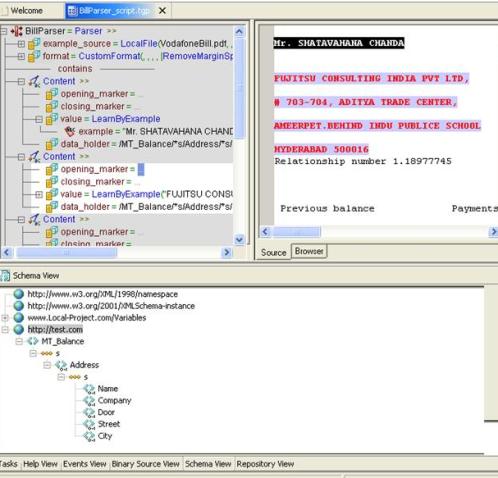
Select the text from Source View and drag to element in Schema.
Here Mr. SHATAVAHANA CHANDA is a text selected from source pdf file and drag to element ‘Name’ in the Schema view.
Similarly simply drag the remaining Address content.
Select text “FUJITSU CONSULTING INDIA PVT LTD,” and drag to element ‘Company’ in schema
Select text “# 703-704, ADITYA TRADE CENTER,” and drag to element ‘Door’ in schema
Select text “AMEERPET.BEHIND INDU PUBLICE SCHOOL” and drag to element ‘Street’ in schema
Select text “HYDERABAD 500016” and drag to element ‘City’ in schema
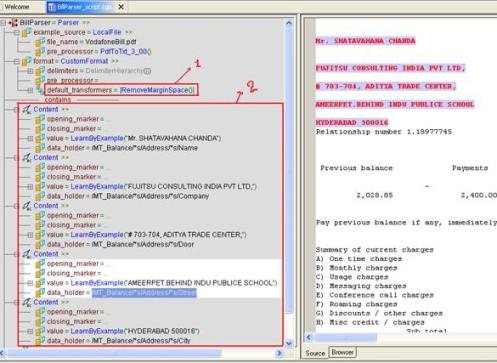
As mentioned above at Mark1: If the parameter default_transformers = RemoveMarginSpace () then it removes the unwanted margin spaces. This option makes easy to parse the file.
At Mark2: Content is used to parse the content on file and having options like
A. (opening_marker,closing _marker) which accepts numeric values this is used to parser the content with in the limit, let’s say if (opening_marker=0,closing_marker=10)then it will parse the content on file only within the limit. We can see more about this in next scenario.
B. In the current scenario we have chosen value = LearnByExample(“ <Text selected from File>“)
C. data_holder is mandatory here, why because you should mention the schema path to identify which element the selected content has to pass.
Most preferable method is (Method-2(A, C)) than (Method-1(B, C)), because if you follow (Method-1(B, C)) it will be fine if customer name is Mr. SHATAVAHANA CHANDA but in real time cases Vodafone can have multiple customers and if they want to process all the bills then it varies and gives error saying can’t parse the file because customer name and his address will be different. So better to follow the Method-2 as shown below.
Method-2: Parsing using Insert Offset Content
So to avoid that simply follow (step2 and step3) as shown
After setting the default_transformers = RemoveMarginSpace() then go to Source view at right side and select the text and right click and say Insert Offset Content
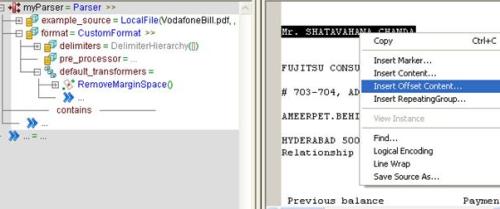
Here customer Name Mr. SHATAVAHANA CHANDA is opened at mark 245 and Closes at mark 22 and then mention the data_holder parameter.
Now select the Company “FUJITSU CONSULTING INDIA PVT LTD” right click and say Insert Offset Content
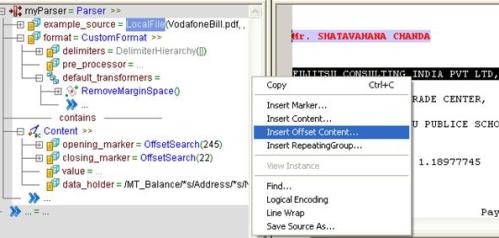
Similarly follow the same steps for remaining content.
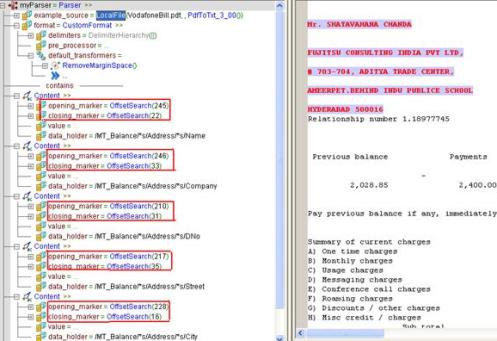
If you observe the above screen shot I haven’t use the option called ‘value’. I used only (opening_marker,closing_marker and data_holder)parameters.
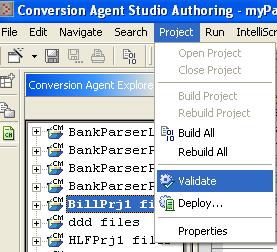
Save and validate the project.
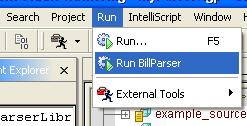
Now run the Parser as shown below.
Now check the output.xml
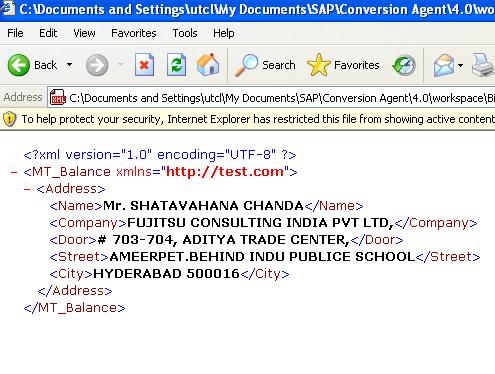
This shows the result in xml format when you parse the PDF file.
The next part talks about Deploying Conversion Agent project.